CPU-Only LLM/SLM Training | NativeLink Open Source Contribution
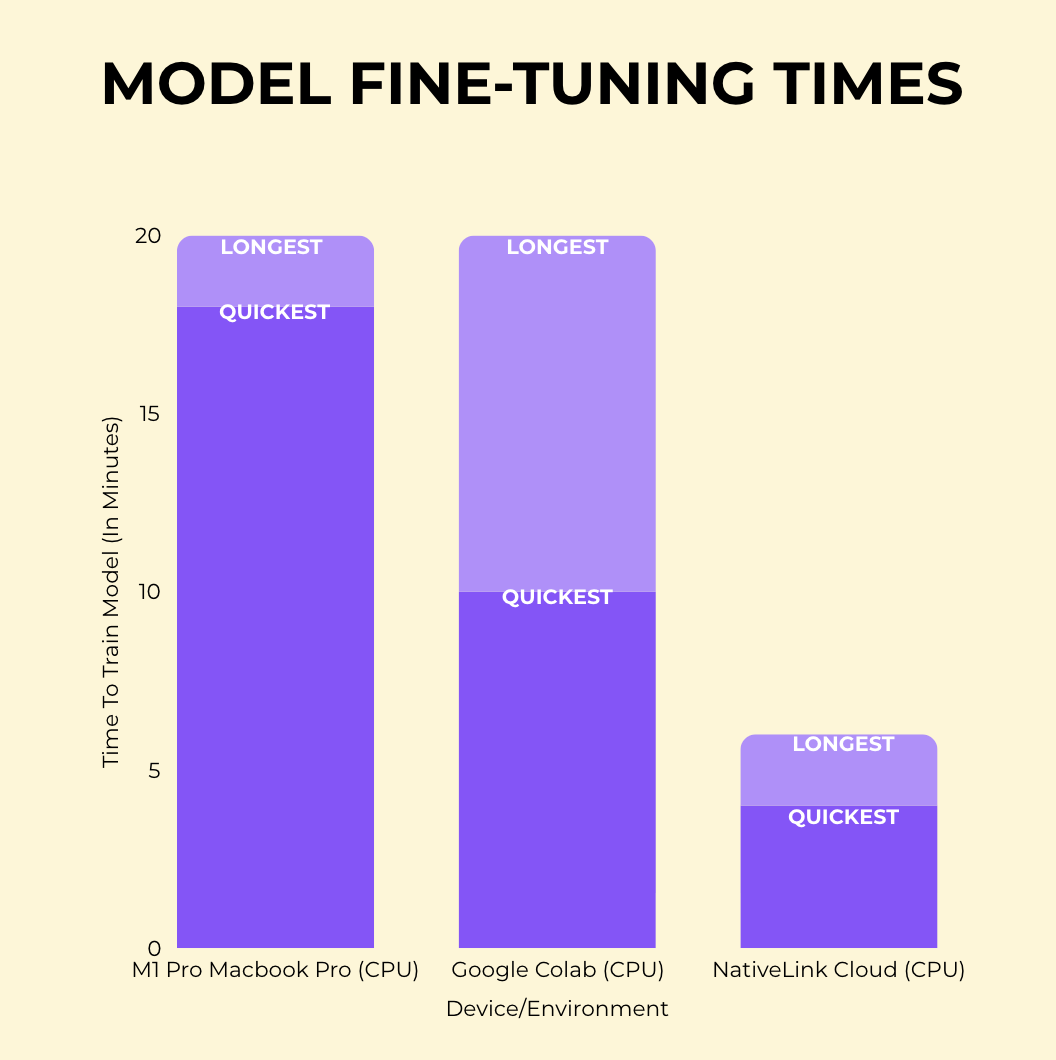
The Human Story:“Every startup shouldn’t need VC money just to train a decent AI model. I proved you can fine-tune language models on laptop CPUs and get better results than Google Colab’s GPUs.”
The Plot Twist: NativeLink’s CEO asked me to showcase model weight caching. I discovered it was fundamentally impossible due to training randomness requirements. Instead of admitting failure, I pivoted to something better.
The Discovery: Their remote execution system was accidentally creating the most efficient CPU-based training environment I’d ever seen. Free tier outperforming Google’s paid GPU offerings.
The Impact:
Technical: Blog post gained 3x expected engagement
Business: Attracted 2 major enterprise clients
Career: Job offer + hero section tutorial request
Community: Gave smaller teams a fighting chance against big tech budgets
The Philosophy:“When the original plan doesn’t work, the best engineers don’t just pivot—they discover something better.”
Tech Stack: Bazel, NativeLink, Language Models, CPU Optimization